
Hugging Face Deep RL Course
Back in December, Hugging Face released an eight unit course covering the fundamentals of Deep Reinforcement Learning. The course covers fundamental theories of Deep RL, core libraries and gives you hands-on experience training your own agents in unique environments ranging from classical control problems all the way to video games like Space Invaders and even Doom!
As opposed to a more classical graduate course like OMSCS's CS-7642, this course puts a larger emphasis on major advancements in the past couple of years that deep learning techniques have introduced to the field. The course covers the following topics:
- Q-Learning, Deep Q-Learning and MC vs TD Learning
- Policy Gradient with REINFORCE
- Actor-Critic Methods
- Multi-Agent Reinforcement Learning
- Proximal Policy Optimization
I'll try to highlight the portions of the course that I found the most interesting or were particularily unique to this course.
Units 1-3: Q-Learning, Deep Q-Learning and MC vs TD Learning
The course first formulates the reinforcement learning problem and the basic paradigms of solving RL problems. We first focus on two paradigms within the Model-free RL algorithms: Policy-based Methods vs Value-based methods.

We start off with Value-Based methods, where we want to learn a value function that maps state to it's expected value. The course reviews the Bellman Equation, which defines how one can recursively calculate the value of any given state. We then briefly look at two major learning paradigms of training value-based methods: Monte Carlo Learning - where you update your value function based on an entire episode of data or Temporal Difference (TD) Learning - where we update our value every n-steps.
The course then builds on this to introduce Q-Learning, which is an off-policy value-based method with TD(0) learning. We implement Q-learning from scratch and solve some basic OpenAI gym problems like Frozen Lake and Taxi Driving.
One major limitation of Q-learning is it's a tabular method which stores a value for each state-action pair, which is very memory intensive for problems with high state and action space dimensionality. The key innovation with the advent of deep learning is we can now approximate the Q-table with a deep neural network.
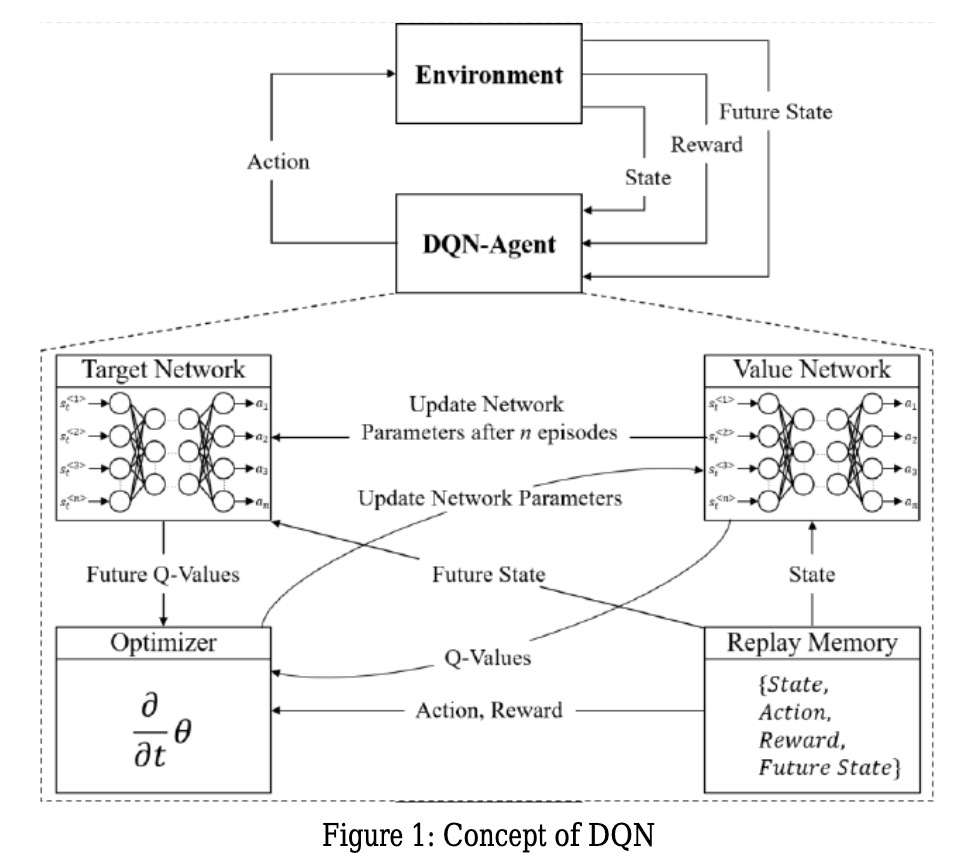
Similar to my work in Georgia Tech's CS-7642 course, we implement our own DQN network based on Mnih et al. Their paper introduces the concept of Experience Replay, which acts as a buffer to store previous experiences and lets the network train on a larger range of samples, rather than the sequential experiences it gets during a normal training episode. Minh et al. also adds the concept of a target network, which helps stabilise training. With a single network we are both shifting the Q-values and the TD target with each update. By having a separate network, we can model the TD target separately and avoid oscillations during training.
Understanding these concepts, we train a agent levering stable-baselines3 to play Space Invaders!
Unit 4: Policy Gradient with REINFORCE
A second approach to Reinforcement learning is to try to learn the policy function itself rather than approximating through a value function. To do this we parameterize the policy, typically modelling it as a probability distribution over a set of actions (stochastic policy). You can now model the policy with a function or neural network and optimise the function by maximising the performance of the policy using gradient ascent.
TODO: Write-up on Policy Gradient Theorem Derivation
To explore Policy Gradient methods, we first implement the REINFORCE algorithm which is a basic Monte-Carlo approach that estimates your return through multiple sample trajectories.
We then train two agents to solve the classic Cart Pole problem and also Flappy Bird!
Unit 6: Actor-Critic Methods
One downside to the REINFORCE algorithm is it's high variance since it relies on Monte-Carlo sampling. To mitigate this you need to sample over a large number of trajectories, which reduces sample efficiency and is cost prohibitive.
One methodology that tries to combat this is the Actor-Critic process, which attempts to combine both Policy-based and Value-based methods. You train an Actor which tries to learn our policy function, and also a Critic, which can also learn a value function which assists the policy by measuring how good each action was taken. By knowing how good each policy update is, we reduce gradient variance.
We then train two agents to solve several classic control problems from the PyBullet and Panda-Gym with Stable Baselines 3 and A2C.
Unit 7: Multi-Agent Reinforcement Learning
We take a brief detour into the world of Multi-Agent RL. The courses treatment of this problem space is very brief compared to Georgia Tech CS-7642's coverage, as we only briefly review several common implementation patterns. There's no exploration of the Game Theory underpinnings of this problem space.
The most interesting part of this course is the introduction of Self-Play and leveraging multiple copies of our agent to learn an train itself. We briefly look into the MLAgents library which leverages the Unity Game Engine to train agents in pre-made environments. The library predetermines matches between different copies of our Agent based on their ELO. It the continually matches agents against each other and progressively each agent should start gradually improving and learning from the process!
Unit 8: Proximal Policy Optimization
Any Deep RL course wouldn't be complete without looking at Proximal Policy Optimization (PPO), a state-of-the-art RL policy optimization algorithm. It's model-free, few hyperparameters and typically performs very well on most RL problems out of the box.
PPO and it's algorithmic brethren approach the RL problem by trying to converge on an optimal policy by avoiding to have too many large policy updates during training. This is primarily motivated by empirical observations that smaller updates tend to converge to an optimal solution and larger policy updates lead to "falling off a cliff" and having no chance of recovering to a previously better policy. PPO achieves this by enforcing a constraint on it's objective function:
TODO: insert clip objective function
We implement our own version of PPO with CleanRL as a reference implementation. We check our implementation on the classic Lunar Lander problem:
Finally to demonstrate the versatility of PPO, we try out PPO with the SampleFactory library and train an agent to play Doom!
Conclusion & Next Steps

Completing all 8 units and having your 12 models pass the required benchmark will reward you with a Certificate of completion. Have all your assignments pass at 100% will get you an honors certificate!
This course only briefly explored the world of Reinforcement Learning. For myself, I'm going to explore multi-agent systems, explore building a RHLF system and applications with LLMs, read up on Decision Transformers and play around with MineRL. I'd like to also explore building my own game adapter like integrating Mupen64 and Starfox 64 into a RL training library.
Member discussion