
CS-7643 Deep Learning
Instructor(s): Zsolt Kira
Course Page: Link
CS-7643 is a foundational course for the OMSCS Machine Learning specialization. It largely follows the curriculum of similar Deep Learning courses like CS231n from Stanford, going through the evolution of deep learning through Computer Vision lens. We cover Image Classification, Perceptrons, Backpropogation, Convolutional Neural Networks, Recurrent Neural Networks, Deep Reinforcement Learning and finally Attention and Transformers.
The most interesting part of the course was special topics covered by researchers from Meta AI. We also had the chance to meet them virtually during office hours and ask questions regarding their research. I was able to meet some of the collaborators from on the No Language Left Behind translation model that can translate from over 200 different languages!
I took the summer variation of the course which has 1 less assignment than the regular 4 during the Fall/Spring semesters. The course still culminated in a final open-ended group project. Each assigment consisted of basic proof or excerises from the past weeks lecture topics, a paper review, and a coding assignment with a substantial experimental and analysis component. I'll briefly cover the most interesting parts of only the papers I reviewed as assignment contents are still confidential.
1) Weight Agnostic Neural Networks
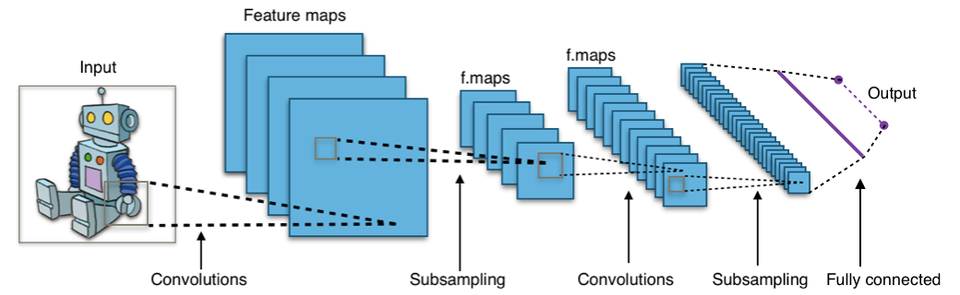
The paper demonstrates a novel network search algorithm that can solve a given machine learning problem without any explicit weight training. They demonstrate that this method is able to find minimal architectures that can solve reinforcement learning tasks like 2D bipedal walking and driving. They also demonstrate it can find architectures to solve supervised learning problems like MNIST digit classification. The results of this research seem deeply connected to learning and evolution. It appears to signal that our brains may not actually be giant general purpose learning machines and the neural architecture of our brains may bias ourselves towards specific ways of learning. In my mind, this could even indicate different modes of thought or reasoning that are beyond our human comprehension due to limitations of our existing brain structure and architecture.
We’ve also seen this in the history of deep learning innovations where novel architectures seem to be the triggering point for large improvements in performance (RNN, LSTM, CNNs, Transformers, Diffusion Networks, etc...) We are also constrained by the limitations of our search algorithms as our best method remains gradient descent optimization. New search algorithms could potentially unlock further innovations in deep learning.
2) Taskonomy: Disentangling Task Transfer Learning
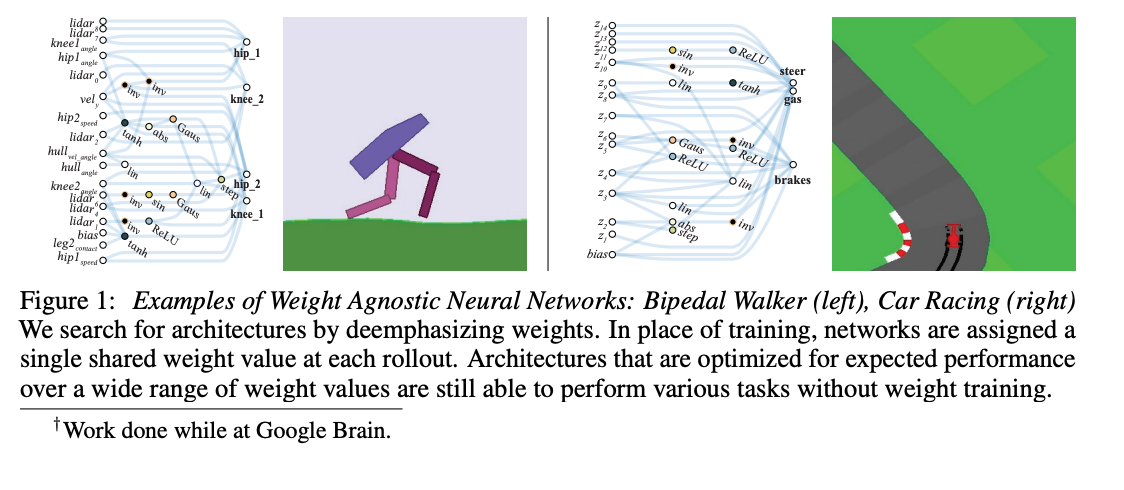
In this paper, Zamir et al. the authors explore the structure and relationships between different visual learning tasks via transfer learning. They use a fully computational approach to model the relationships between twenty six different semantic tasks such as finding surface normal, 2D segmentation, edge detection, etc... The authors also demonstrate that taxonomy transfer generalises to novel tasks that are not in their trained task dictionary and they also train the taxonomy on other datasets to show that the what they found is generalizable. This leads the reader to conclude that there is an inherent structure in visual tasks that are being learned by the neural networks and that this structure can be used to model redundancies across different tasks and reused via transfer learning.
This study seems to indicate that deep neural networks are capable of learning high level features or concepts that roughly map to our own perceived relationships or actual physical relationships between different visual tasks (surface normal to depth maps via derivative). In order to learn where to transfer from a new learning task, we may want to leverage our own prior knowledge to find networks that were trained on similar tasks on a conceptual level.
3) Do Vision Transformers See Like Convolutional Neural Networks?
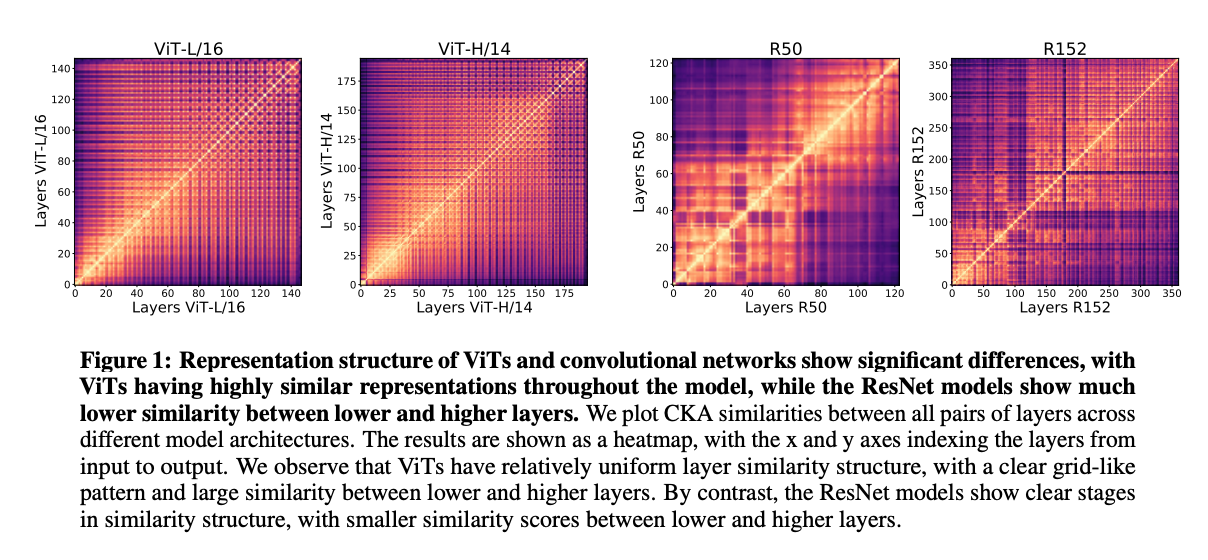
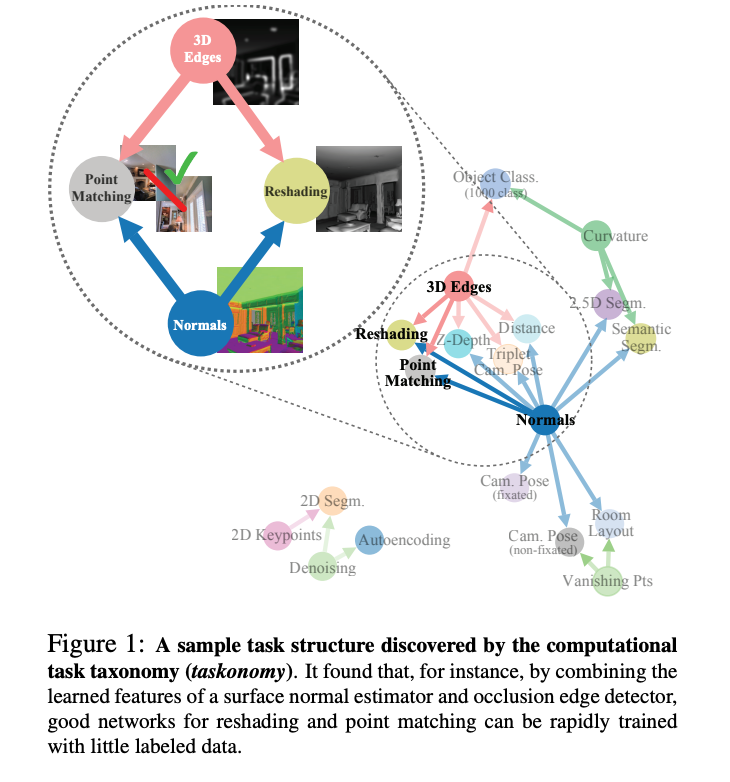
This paper identifies key structural differences in the features learned from Resnet based CNN’s versus Vision Transformers (ViTs). They identify that ViTs are better at incorporating global information than ResNets at lower layers. The paper identifies key parts of the transformer architecture that lead to such performance such as the importance of information flow through skip connections and how global average pooling vs CLS token helps maintain spatial localization.
My personal takeaway is that the historical motivations for convolutional neural networks and finding operations that mimic our ‘common sense’ understanding of existing vision systems are likely incorrect. The paper suggests that the power of attention and transformers in representing global features is more important and can lead to potentially better performance. Similar to my learnings from Paper 1, network architecture is probably the largest contributing factor of a model's representational power. Future research should focus on different architectures that can further improve model performance.
Final Project - AlphaZero & Connect 4
For my final project, I worked with another classmate to study an implementation of AlphaZero that could play Connect 4. The most fascinating part of this model is that it leverages Deep Reinforcement learning and self-play to learn how to play the game. This means that all the concepts it learns were self-taught without any human input or bias!
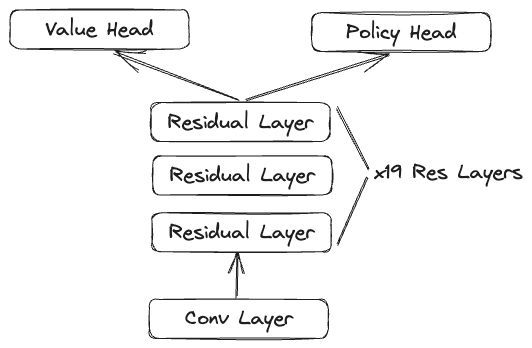
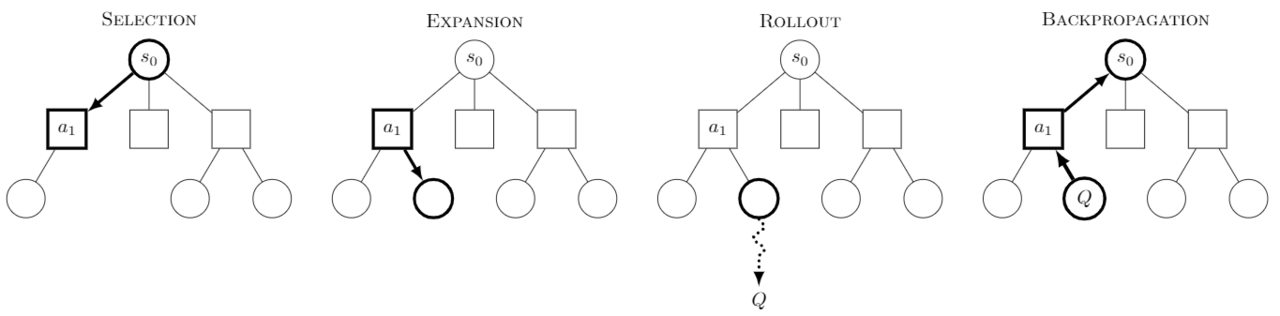
We did an abaltion study to understand how much it architecture and reliance on Monte-Carlo Tree Search affected performance. We also explored using linear probes to see if we could tease out if it was learning any specific game concepts from training. I hope to find some free time in the coming months to continue in that vein of research.
Member discussion