Tweeting with Markov Chains


I'm not sure why I find this so surprising, but it's a somewhat trivial task to write a program that can spew out somewhat coherent sentences, as long as you have a large corpus to work off.
Markov Chains
Markov Chains are essentially state machines with probabilities assigned to each of it's state transitions.

For example, using the Markov Chain shown above, if it were sunny today, there would be a 70% chance it would be rainy tomorrow, and a 30% chance it would still be sunny. If one were to continue to traverse the chain, they would get a sequence of weather patterns like:
'sunny', 'rainy', 'rainy', 'sunny', ...
If the probabilities were reasonable, the sequence of weather patterns should be reflect your 7-day weather forecast!
The Bot
We can apply this same methodology to generate some tweets! First we need some source material. I had scraped around 110,000 game reviews off Metacritic for another project I was working on.
First we need to split up our corpus into individual tokens. We could split it up at several granularities, like per-character, per-word, or even per-sentence. As with most things, there's a trade-off on both ends. Tokenize by character, and it's you'll get nonsensical gibberish. If you split by sentence, you're essentially just chaining together pieces from your source material. Let's try at the word level for now:
"""
Using NLTK for convenience. You can use split() ¯\_(ツ)_/¯
"""
tokenizer = nltk.tokenize.RegexpTokenizer(r'\w+|[^\w\s]+')
tokenized_content = tokenizer.tokenize(review_file.read())
Now that we've tokenized our corpus, we need to make a decision on how we wan't to represent each state. We can use a single word/token as the state:
to, be, or, not, to, be, …
We can make it a bit more complex and do each pair of words:
to be, be or, or not, not to, to be, …
And pushing it even further, triples:
to be or, be or not, or not to, not to be, …
The technical term for this grouping of tokens is n-grams. Picking the correct n will impact the performance of your model. Pick an extremely large n, and your model will be very biased towards certain sequences. Pick too small an n and your model will spew out crap, since there's so much variability. Tri-grams are usually a good bet for decent sized corpuses, but for smaller ones bi-grams perform better.
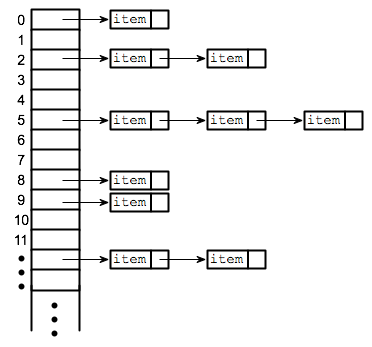
Now that we've decided on what the states will look like in our Markov Chain, how do we go about representing it in a data structure? One simple way is to use a Hash Table/Dictionary where the keys are states in the Markov Chain, and the key's value are the possible transitions, represented by an array of keys (which assumes that each transistion has a uniform probability.
def train(self):
for w1, w2, w3 in self.triplets(tokenized_content):
key = (w1, w2)
if key in self.model:
self.model[key].append(w3)
else:
self.model[key] = [w3]
Now that we have our Markov Chain ready to go, we'll just need to start off at some random state, and traverse the chain to generate some tweets!
def generate_tweet(self):
w1, w2 = random.choice(self.model.keys())
gen_words = []
tweet_length = 0
while tweet_length <= 100:
gen_words.append(w1)
tweet_length += len(w1) + 1
w1, w2 = w2, random.choice(self.model[(w1, w2)])
gen_words.append('#GameReview')
return reduce(self.join_tokens, gen_words)
The resulting tweets:
Source can be found here: https://gist.github.com/ben-yu/919e843ac4df8d0fccee